2 Statistical Learning
Chapter 2 formalizes the concept of statistical learning by introducing the general statistical model used for modelling the relationship between \(Y\) and \(X = (X_1, X_2, \dots, X_p)\), which can be written as
\[ Y = f(X) + \epsilon. \tag{2.1} \]
Here:
- \(Y\) represents the response variable in our data set
- \(X\) represents the set of variables in our data set
- \(X_p\) represents the \(p\)th variable in our data set
- \(f(\dots)\) represents a fixed but unknown function of its input(s)
- \(\epsilon\) represents a random error term which is independent of \(X\) and has mean zero
The goal of statistical learning is to estimate \(f\). There are two main reasons for estimating \(f\): prediction and inference. Depending on whether our ultimate goal is prediction, inference, or some combination of the two, different methods for estimating \(f\) may be appropriate. In general, there is a trade-off between prediction accuracy and model interpretability. Models that make more accurate predictions tend to be less interpretable, and models that are more interpretable tend to make less accurate predictions (although this is not always the case, due to the potential for overfitting in highly flexible models).
The methods we use to estimate \(f\) can be characterized as either parametric or non-parametric. Parametric methods involve a two-step model-based approach: First we make an assumption about the functional form of \(f\) (e.g., we could assume \(f\) is linear). Second we fit (train) the model to our training data in order to estimate the parameters. Non-parametric methods do not make any assumptions about the functional form of \(f\). Instead they try to find an estimate of \(f\) that gets close to the data points without being too rough or wiggly.
2.1 Prediction
Because the error term \(\epsilon\) averages to zero, the general statistical model for predicting \(Y\) from \(X = (X_1, X_2, \dots, X_p)\) can be written as
\[ \hat Y = \hat f(X). \tag{2.2} \]
Here:
- \(\hat Y\) represents the resulting prediction for \(Y\)
- \(\hat f\) represents our estimate for \(f\)
When our goal is only to predict, we do not typically need to concern ourselves with the exact form of \(\hat f\) provided that it accurately predicts \(Y\). The accuracy of \(\hat Y\) as a prediction for \(Y\) depends on two sources of error: reducible error and irreducible error. The error in our model attributable to \(\hat f\) is reducible because we can potentially improve the accuracy of \(\hat f\) for estimating \(f\) by using a more appropriate statistical learning technique. However, the error in our model attributable to \(\epsilon\) is irreducible because \(Y\) is also a function of \(\epsilon\), and \(\epsilon\) is independent of \(X\), so no matter how well we estimate \(f\), the variability associated with \(\epsilon\) will still be present in our model. This variability may come from unmeasured variables that are useful for predicting \(Y\), or from unmeasurable variation. Irreducible error places an (often unknowable) upper bound on the accuracy of our prediction for \(Y\).
2.2 Inference
When our goal is to understand the relationship between \(Y\) and \(X = (X_1, X_2, \dots, X_p)\), we do need to concern ourselves with the exact form of \(\hat f\). Here the form of \(\hat f\) can be used to identify:
- Which predictors are associated with the response
- the direction (positive or negative) and form (simple or complex) of the relationship between the response and each predictor
2.3 Assessing Model Accuracy
No one statistical learning approach performs better than all other approaches on all possible data sets. Because of this, care needs to be taken to choose which approach to use for any given data set to produce the best results. A number of important concepts arise when selecting a statistical learning approach for a specific data set:
- Measuring the quality of fit
- The bias-variance trade-off
2.3.1 In the Regression Setting
In the regression setting, the most commonly used quality of fit measure for training data is the mean squared error \(\mathit{MSE}\), given by
\[ \mathit{MSE}_{\mathrm{training}} = \frac 1 n \sum_{i = 1}^n (y_i - \hat f(x_i))^2, \tag{2.3} \]
where \(\hat f(x_i)\) represents the prediction that \(\hat f\) gives for the \(i\)th observation. When predicted responses are very close to true responses the \(\mathit{MSE}\) will be small; When predicted responses are very far from true responses the \(\mathit{MSE}\) will be large. We generally do not really care about this value because accurately predicting data we have already seen is not particularly useful.
when our goal is to assess the accuracy of predictions when we apply our method to previously unseen test data, we can compute the mean squared error for test observations, given by
\[ \mathit{MSE}_{\mathrm{testing}} = \frac 1 n \sum_{i = 1}^n (y_0 - \hat f(x_0))^2, \tag{2.4} \]
where \((x_0, y_0)\) is a previously unseen test observation not used to train the statistical learning model. We want to choose the model that gives the lowest test \(\mathit{MSE}\) by minimizing the distance between \(\hat f(x_0)\) and \(y_0\). When a test data set is available then we can simply evaluate Equation (2.4) and choose the statistical learning model where \(\mathit{MSE}\) is the smallest. When a test data set is not available then we can use cross-validation, which is a method for estimating test \(\mathit{MSE}\) using the training data set.
The expected test \(\mathit{MSE}\) for a given value \(x_0\) can always be decomposed into the sum of three fundamental quantities: the variance of \(\hat f(x_0)\), the squared bias of \(\hat f(x_0)\), and the variance of the error term \(\epsilon\), written as
\[ E \bigl(y_0 - \hat f(x_0) \bigr)^2 = \mathrm{Var}(\hat f(x_0)) + [\mathrm{Bias(\hat f(x_0))}]^2 + \mathrm{Var}(\epsilon), \tag{2.5} \]
where the notation \(E \bigl(y_0 - \hat f(x_0) \bigr)^2\) defines the expected test \(\mathit{MSE}\) at \(x_0\). The overall expected test \(\mathit{MSE}\) is given by averaging \(E \bigl(y_0 - \hat f(x_0) \bigr)^2\) over all possible values of \(x_0\) in the test data set.
The variance of \(\hat f\) refers to the amount by which \(\hat f\) would change if we estimated it using a different training set. The bias of \(\hat f\) refers to the error that is introduced by approximating a real-life problem with a much simpler model. In general, as models become more flexible, the variance will increase and the bias will decrease. The relative rate of change of the variance and bias determines whether the test \(\mathit{MSE}\) increases or decreases. Because the variance and bias can change at different rates in different data sets, the challenge lies in finding a model for which both the variance and bias are lowest.
2.3.2 In the Classification Setting
In the classification setting, the most commonly used quality of fit measure for training data is the error rate, given by
\[ \frac 1 n \sum_{i = 1}^n I(y_i \ne \hat y_i). \tag{2.6} \]
Here:
- \(\hat y_i\) is the predicted class label for the \(i\)th observation using \(\hat f\)
- \(I(y_i \ne \hat y_i)\) is an indicator variable that equals one if \(y_i \ne \hat y_i\) (incorrectly classified) and zero if \(y_i = \hat y_i\) (correctly classified)
The test error rate for a set of test observations \((x_0, y_0)\) is given by
\[ \frac 1 n \sum_{i = 1}^n I(y_0 \ne \hat y_0), \tag{2.7} \]
where \(\hat y_0\) is the predicted class label that results from applying the classifier to the test observation with predictor \(x_0\).
The bias-variance trade-off is present in the classification setting too; when variance and bias are lowest then the test error rate will be at its smallest for a given data set.
2.4 Exercises
Prerequisites
To access the data sets and functions used to complete the Chapter 2 exercises, load the following packages.
Conceptual
Exercise 2.1 For each of parts (a) through (d), indicate whether we would generally expect the performance of a flexible statistical learning method to be better or worse than an inflexible method. Justify your answer.
- The sample size \(n\) is extremely large, and the number of predictors \(p\) is small.
Answer. Better. A flexible model will generally be able to better estimate the the true \(f\) and avoid overfitting when we have an extremely large sample size and a small number of predictors. The only exception would be if the true \(f\) is linear, then an inflexible model would generally perform better; however, most real world relationships are not linear, so the lower bias of a flexible model will generally lead to a better quality of fit.
- The number of predictors \(p\) is extremely large, and the number of observations \(n\) is small.
Answer. Worse. A flexible model will generally lead to overfitting of our training data when the number of predictors is large and the sample size is small. An inflexible model is less likely to lead to overfitting in this scenario, so it will generally do a better job of giving accurate predictions on new observations than the flexible but overfit model.
- The relationship between the predictors and response is highly non-linear.
Answer. Better. A flexible model will generally be able to fit a highly non-linear relationship better than an inflexible model because the relative rate of decrease in bias tends to be much greater than the relative increase in variance when \(f\) is highly non-linear. The left and right plots in Figure 2.12 on Page 36 of the book demonstrate this nicely.
- The variance of the error terms, i.e. \(\sigma^2 = \mathrm{Var}(\epsilon)\), is extremely high.
Answer. Worse. A flexible model will generally lead to overfitting of our training data when the variance of the error terms is extremely high. Because \(Y\) is partly a function of \(\epsilon\), when the variance of the error terms is extremely high then the variance of \(Y\) will also be extremely high, mainly due to random error. A flexible model that tries to find patterns in this noise is more likely to pick up on patterns that are caused by random chance rather than true properties of the unknown function \(f\). The bias of an inflexible model is preferable in this situation, as it will give more stable predictions in the long run, which is likely preferable to making the essentially random predictions a flexible model would give in these circumstances.
Exercise 2.2 Explain whether each scenario is a classification or regression problem, and indicate whether we are most interested in inference or prediction. Finally, provide \(n\) and \(p\).
- We collect a set of data on the top 500 firms in the US. For each firm we record profit, number of employees, industry, and the CEO salary. We are interested in understanding which factors affect CEO salary.
Answer. Regression, inference, \(n = 500\), \(p = 3\).
- We are considering launching a new product and wish to know whether it will be a success or failure. We collect data on 20 similar products that were previously launched. For each product we have recorded whether it was a success or failure, price charged for the product, marketing budget, competition price, and ten other variables.
Answer. Classification, prediction, \(n = 20\), \(p = 13\).
- We are interested in predicting the % change in the USD/Euro exchange rate in relation to the weekly changes in the world stock markets. Hence we collect weekly data for all of 2012. For each week we record the % change in the USD/Euro, the % change in the US market, the % change in the British market, and the % change in the German market.
Answer. Regression, prediction, \(n = 52\), \(p = 3\).
Exercise 2.3 We now revisit the bias-variance decomposition.
- Provide a sketch of a typical (squared) bias, variance, training error, test error, and Bayes (or irreducible) error curves, on a single plot, as we go from less flexible statistical learning methods towards more flexible approaches. The \(x\)-axis should represent the amount of flexibility in the method, and the \(y\)-axis should represent the values for each curve. There should be five curves. Make sure to label each one.
Answer.
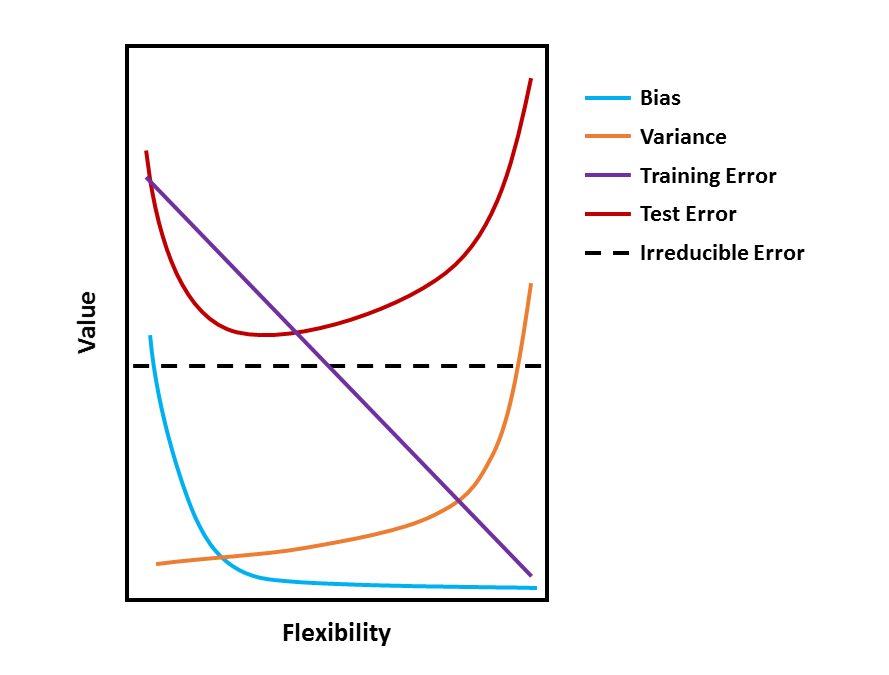
- Explain why each of the five curves has the shape displayed in part (a).
Answer. The value of each measure in part (a) changes at different rates and in different directions as we go from less flexible statistical learning methods towards more flexible approaches. Broadly, this is why each curve has a different shape. Specifically:
- Bias refers to the error that is introduced by approximating a real-life problem with a much simpler model. In general, bias will decrease as models become more flexible, because more flexibility will lead to better approximations of a real-life problem, reducing error.
- Variance refers to the amount by which \(\hat f\) would change if we estimated it using a different training set. In general, variance will increase as models become more flexible, because a more flexible model will pick up patterns in the training data better which may differ between training sets.
- Training error refers to the quality of fit of the model to the training data. In general, training error will steadily increase as models become more flexible, because more flexibility will allow the model to closely follow the training data.
- Test error refers to the quality of fit of the trained model to the test data. In general, test error will be U-shaped because of the bias-variance trade-off.
- Irreducible error refers to random error that is independent of \(X\). Because irreducible error is independent of \(X\), it remains stable regardless of model flexibility.
Exercise 2.4 You will now think of some real-life applications for statistical learning.
- Describe three real-life applications in which classification might be useful. Describe the response, as well as the predictors. Is the goal of each application inference or prediction? Explain your answer.
Answer.
Predicting whether or not a customer is likely to purchase more if items are discounted on a web store. The predictor would be whether or not they are likely to purchase more items; the predictors would be purchase history of discounted and full price items, and purchase frequency. The goal would be prediction in order to determine whether to show discounts to a customer more or less frequently.
Understanding what demographic groups enjoy Star Trek. The response would again be whether or not someone is a Trekkie; the predictors would be various demographic variables such as age, gender identity, ethnicity, and so on. The goal would be inference about whether Star Trek appeals to specific groups or is enjoyable to a diverse audience.
Understanding what kind of people like raisin cookies. The response would be whether or not someone likes raisin cookies; the predictors would be levels of psychopathy and sadism. The goal would be inference about whether people who like raisin cookies are secretly evil.
- Describe three real-life applications in which regression might be useful. Describe the response, as well as the predictors. Is the goal of each application inference or prediction? Explain your answer.
Answer.
Predicting the temperature tomorrow where you live. The response would be temperature in degrees Celsius; the predictors would be average temperature where you live in the past seven days, the latitude, longitude, and altitude of where you live, and the month of the year. The goal would be prediction in order to decide what outfit you might wear tomorrow.
Understanding what aspects of a video game lead to people playing it longer. The response would be minutes spent playing a game; the predictors would be game genre, whether the game is an original or sequel, whether the game is singleplayer, multiplayer, or both, and the game developer. The goal would be inference to determine what makes a game engaging.
Predicting how long it would take for an injury to heal. The response would be time to heal; the predictors would be injury severity, age, and other indicators of physical health. The goal would be prediction in order to give patients an idea the time to recovery.
- Describe three real-life applications in which cluster analysis might be useful.
Answer.
Identifying whether brain activity is more similar within or between individuals. The predictor variable would a repeated measure of functional connectivity. The goal would be inference in order to see whether brain activity recordings cluster together by individual.
Identifying whether patients with depression can be classified into subgroups. The predictor variables would be responses on a depression inventory. The goal would be inference in order to understand whether the depression inventory measures multiple types of depression.
Identifying whether species in families of animals identified by biologists aligns with those species’ genomes. The predictor variable would be species genome. The goal would be understanding whether clusters identified through observation align with clusters identified through genetics.
Exercise 2.5 What are the advantages and disadvantages of a very flexible (versus a less flexible) approach for regression or classification? Under what circumstances might a more flexible approach be preferred to a less flexible approach? When might a less flexible approach be preferred?
Answer. The advantage of a very flexible approach is less bias, so the model better approximates reality, and typically better prediction. The disadvantage is higher variance and the potential for overfitting. A more flexible model might be preferred if the goal of statistical learning is prediction. A less flexible approach might be preferred if the goal of statistical learning is inference, as simpler models tend to be easier to understand.
Exercise 2.6 Describe the differences between a parametric and a non-parametric statistical learning approach. What are the advantages of a parametric approach to regression or classification (as opposed to a non-parametric approach)? What are its disadvantages?
Answer. Parametric methods involve a two-step model-based approach: First we make an assumption about the functional form of \(f\) (e.g., we could assume \(f\) is linear). Second we fit (train) the model to our training data in order to estimate the parameters. The advantage of this is that it is easier to estimate a set of parameters than it is to fit an entirely arbitrary function \(f\). The disadvantage is that the model we choose will usually not match the true unknown form of \(f\), which can lead to poor estimates if we are too far from the true \(f\).
Non-parametric methods do not make any assumptions about the functional form of \(f\). Instead they try to find an estimate of \(f\) that gets close to the data points without being too rough or wiggly. The advantage of this is that it becomes easier to accurately fit a wider range of possible shapes for \(f\). However, the disadvantage of this is that doing so accurately requires a much larger number of observations since the problem of estimating \(f\) to a small number of parameters.
Exercise 2.7 The table below provides a training data set containing six observations, three predictors, and one qualitative response variable.
| Obs. | \(X_1\) | \(X_2\) | \(X_3\) | \(Y\) |
|---|---|---|---|---|
| 1 | 0 | 3 | 0 | Red |
| 2 | 2 | 0 | 0 | Red |
| 3 | 0 | 1 | 3 | Red |
| 4 | 0 | 1 | 2 | Green |
| 5 | -1 | 0 | 0 | Green |
| 6 | 1 | 1 | 1 | Red |
Suppose we wish to use this data set to make a prediction for \(Y\) when \(X1 = X2 = X3 = 0\) using K-nearest neighbours.
- Compute the Euclidean distance between each observation and the test point, \(X1 = X2 = X3 = 0\).
Answer.
The equation for Euclidean distance is given by
\[ d(p, q) = \sqrt{ \sum_{i = 1}^n (q_i - p_i)^2}, \tag{2.8} \]
where \(d(p, q)\) represents the distance between points \(p\) and \(q\) in \(n\) dimensional Euclidean space, and \(q_i\) and \(p_i\) represent Euclidean vectors, starting from the origin of the \(n\) dimensional Euclidean space.
This can be computed in R like so.
euclidean_distance <- function(q, p) sqrt(sum((q - p)^2))
obs_test <- c( 0, 0, 0)
obs_train <- list(
obs_01 = c( 0, 3, 0),
obs_02 = c( 2, 0, 0),
obs_03 = c( 0, 1, 3),
obs_04 = c( 0, 1, 2),
obs_05 = c(-1, 0, 0),
obs_06 = c( 1, 1, 1)
)
lapply(obs_train, function(x) euclidean_distance(obs_test, x))
#> $obs_01
#> [1] 3
#>
#> $obs_02
#> [1] 2
#>
#> $obs_03
#> [1] 3.162278
#>
#> $obs_04
#> [1] 2.236068
#>
#> $obs_05
#> [1] 1
#>
#> $obs_06
#> [1] 1.732051- What is our prediction with \(K = 1\)? Why?
Answer. When \(K = 1\) our prediction for the test point will be whatever training observation is closest to the test point. Observation 5 (Green) is closest so our prediction is that the test point is Green.
- What is our prediction with \(K = 3\)? Why?
Answer. When \(K = 3\) our prediction for the test point is given by the class with highest estimated probability based on the three points in the training data that are closest to the test point. Here observations 5 (Green), 6 (Red), and 2 (Red) are closest, which results in probabilities of 1/3 for the Green class and 2/3 for the Red class. So our prediction is that the test point is Red.
- If the Bayes decision boundary in this problem is highly non-linear, then would we expect the best value for \(K\) to be large or small? Why?
Answer. We would expect a smaller value of K to give the best predictions. But not too small. When \(K = 1\) the KNN decision boundary will be overly flexible, while with a large value of \(K\) it will not be sufficiently flexible.
Applied
Exercise 2.8 This exercise relates to the ISLR2::College data set. It contains a number of
variables for 777 different universities and colleges in the US. The help page ?ISLR2::College for the data set contains a description of the data set and the 18 variables it measures.
- Load the
ISLR2::Collegedata set into R.
# Make sure to preserve the row names with college names in them because they
# might be useful later
college <- as_tibble(ISLR2::College, rownames = NA)
glimpse(college)
#> Rows: 777
#> Columns: 18
#> $ Private <fct> Yes, Yes, Yes, Yes, Yes, Yes, Yes, Yes~
#> $ Apps <dbl> 1660, 2186, 1428, 417, 193, 587, 353, ~
#> $ Accept <dbl> 1232, 1924, 1097, 349, 146, 479, 340, ~
#> $ Enroll <dbl> 721, 512, 336, 137, 55, 158, 103, 489,~
#> $ Top10perc <dbl> 23, 16, 22, 60, 16, 38, 17, 37, 30, 21~
#> $ Top25perc <dbl> 52, 29, 50, 89, 44, 62, 45, 68, 63, 44~
#> $ F.Undergrad <dbl> 2885, 2683, 1036, 510, 249, 678, 416, ~
#> $ P.Undergrad <dbl> 537, 1227, 99, 63, 869, 41, 230, 32, 3~
#> $ Outstate <dbl> 7440, 12280, 11250, 12960, 7560, 13500~
#> $ Room.Board <dbl> 3300, 6450, 3750, 5450, 4120, 3335, 57~
#> $ Books <dbl> 450, 750, 400, 450, 800, 500, 500, 450~
#> $ Personal <dbl> 2200, 1500, 1165, 875, 1500, 675, 1500~
#> $ PhD <dbl> 70, 29, 53, 92, 76, 67, 90, 89, 79, 40~
#> $ Terminal <dbl> 78, 30, 66, 97, 72, 73, 93, 100, 84, 4~
#> $ S.F.Ratio <dbl> 18.1, 12.2, 12.9, 7.7, 11.9, 9.4, 11.5~
#> $ perc.alumni <dbl> 12, 16, 30, 37, 2, 11, 26, 37, 23, 15,~
#> $ Expend <dbl> 7041, 10527, 8735, 19016, 10922, 9727,~
#> $ Grad.Rate <dbl> 60, 56, 54, 59, 15, 55, 63, 73, 80, 52~- Explore the
collegedata.
- Produce a numerical summary of the variables in the data set.
Answer.
skim(college)| Name | college |
| Number of rows | 777 |
| Number of columns | 18 |
| _______________________ | |
| Column type frequency: | |
| factor | 1 |
| numeric | 17 |
| ________________________ | |
| Group variables | None |
Variable type: factor
| skim_variable | n_missing | complete_rate | ordered | n_unique | top_counts |
|---|---|---|---|---|---|
| Private | 0 | 1 | FALSE | 2 | Yes: 565, No: 212 |
Variable type: numeric
| skim_variable | n_missing | complete_rate | mean | sd | p0 | p25 | p50 | p75 | p100 | hist |
|---|---|---|---|---|---|---|---|---|---|---|
| Apps | 0 | 1 | 3001.64 | 3870.20 | 81.0 | 776.0 | 1558.0 | 3624.0 | 48094.0 | ▇▁▁▁▁ |
| Accept | 0 | 1 | 2018.80 | 2451.11 | 72.0 | 604.0 | 1110.0 | 2424.0 | 26330.0 | ▇▁▁▁▁ |
| Enroll | 0 | 1 | 779.97 | 929.18 | 35.0 | 242.0 | 434.0 | 902.0 | 6392.0 | ▇▁▁▁▁ |
| Top10perc | 0 | 1 | 27.56 | 17.64 | 1.0 | 15.0 | 23.0 | 35.0 | 96.0 | ▇▇▂▁▁ |
| Top25perc | 0 | 1 | 55.80 | 19.80 | 9.0 | 41.0 | 54.0 | 69.0 | 100.0 | ▂▆▇▅▃ |
| F.Undergrad | 0 | 1 | 3699.91 | 4850.42 | 139.0 | 992.0 | 1707.0 | 4005.0 | 31643.0 | ▇▁▁▁▁ |
| P.Undergrad | 0 | 1 | 855.30 | 1522.43 | 1.0 | 95.0 | 353.0 | 967.0 | 21836.0 | ▇▁▁▁▁ |
| Outstate | 0 | 1 | 10440.67 | 4023.02 | 2340.0 | 7320.0 | 9990.0 | 12925.0 | 21700.0 | ▃▇▆▂▂ |
| Room.Board | 0 | 1 | 4357.53 | 1096.70 | 1780.0 | 3597.0 | 4200.0 | 5050.0 | 8124.0 | ▂▇▆▂▁ |
| Books | 0 | 1 | 549.38 | 165.11 | 96.0 | 470.0 | 500.0 | 600.0 | 2340.0 | ▇▆▁▁▁ |
| Personal | 0 | 1 | 1340.64 | 677.07 | 250.0 | 850.0 | 1200.0 | 1700.0 | 6800.0 | ▇▃▁▁▁ |
| PhD | 0 | 1 | 72.66 | 16.33 | 8.0 | 62.0 | 75.0 | 85.0 | 103.0 | ▁▁▅▇▅ |
| Terminal | 0 | 1 | 79.70 | 14.72 | 24.0 | 71.0 | 82.0 | 92.0 | 100.0 | ▁▁▃▆▇ |
| S.F.Ratio | 0 | 1 | 14.09 | 3.96 | 2.5 | 11.5 | 13.6 | 16.5 | 39.8 | ▁▇▂▁▁ |
| perc.alumni | 0 | 1 | 22.74 | 12.39 | 0.0 | 13.0 | 21.0 | 31.0 | 64.0 | ▅▇▆▂▁ |
| Expend | 0 | 1 | 9660.17 | 5221.77 | 3186.0 | 6751.0 | 8377.0 | 10830.0 | 56233.0 | ▇▁▁▁▁ |
| Grad.Rate | 0 | 1 | 65.46 | 17.18 | 10.0 | 53.0 | 65.0 | 78.0 | 118.0 | ▁▅▇▅▁ |
- Produce a scatterplot matrix of the first ten columns or variables of the data.
Answer.
college %>%
select(1:10) %>%
ggpairs()
#> `stat_bin()` using `bins = 30`. Pick better value with
#> `binwidth`.
#> `stat_bin()` using `bins = 30`. Pick better value with
#> `binwidth`.
#> `stat_bin()` using `bins = 30`. Pick better value with
#> `binwidth`.
#> `stat_bin()` using `bins = 30`. Pick better value with
#> `binwidth`.
#> `stat_bin()` using `bins = 30`. Pick better value with
#> `binwidth`.
#> `stat_bin()` using `bins = 30`. Pick better value with
#> `binwidth`.
#> `stat_bin()` using `bins = 30`. Pick better value with
#> `binwidth`.
#> `stat_bin()` using `bins = 30`. Pick better value with
#> `binwidth`.
#> `stat_bin()` using `bins = 30`. Pick better value with
#> `binwidth`.
- Produce side-by-side boxplots of
OutstateversusPrivate.
Answer.
college %>%
ggplot(aes(y = Outstate)) +
geom_boxplot() +
facet_wrap(~Private) +
labs(title = "Private universities receive more out of state tuition")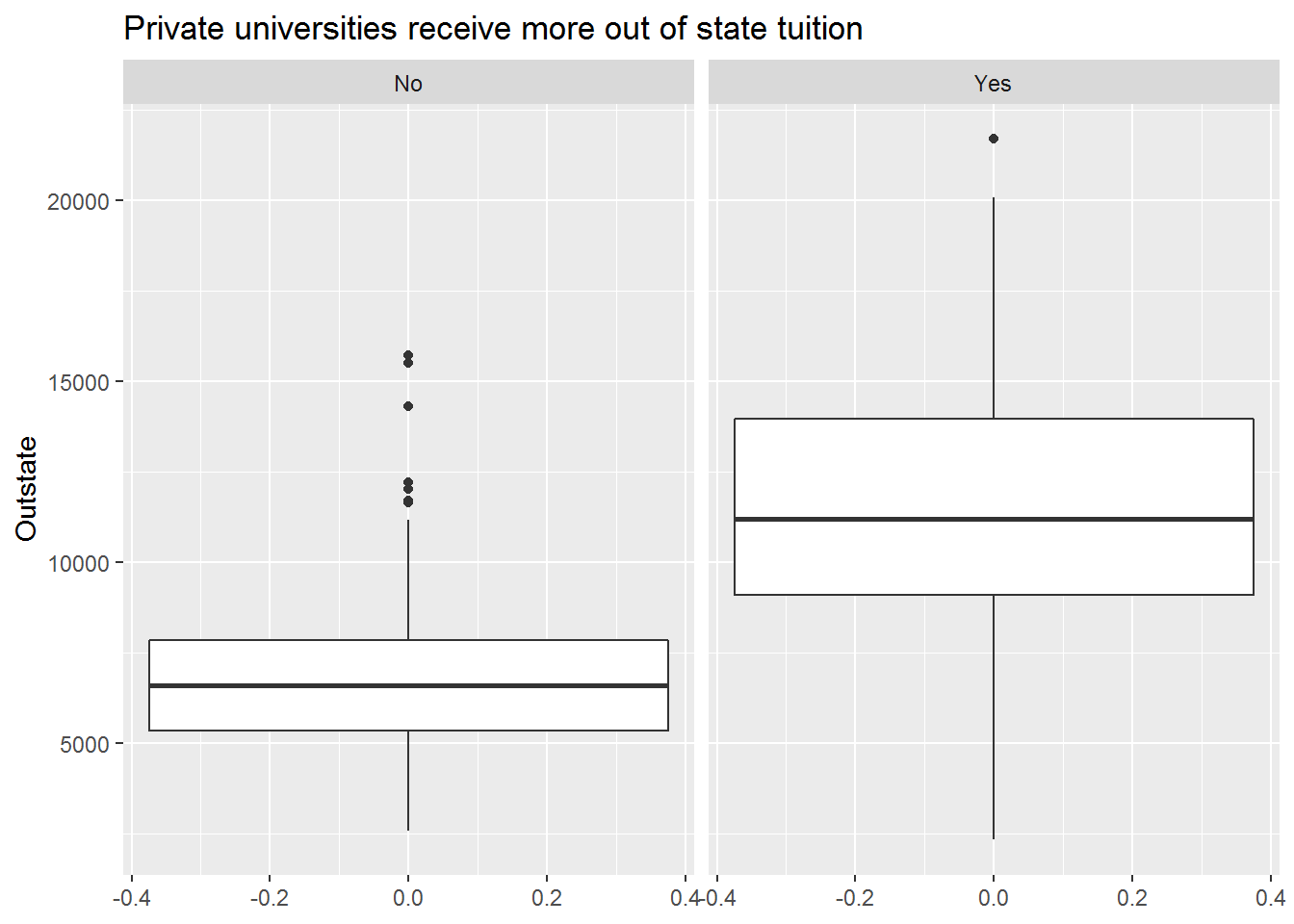
- Create a new qualitative variable, called
Elite, by binning theTop10percvariable. We are going to divide universities into two groups based on whether or not the proportion of students coming from the top 10% of their high school classes exceeds 50%. See how many elite universities there are, then produce side-by-side boxplots ofOutstateversusElite.
Answer.
college %>%
mutate(Elite = if_else(Top10perc > 50, "Yes", "No") %>% as_factor()) %>%
ggplot(aes(y = Outstate)) +
geom_boxplot() +
facet_wrap(~Elite) +
labs(title = "Elite universities receive more out of state tuition")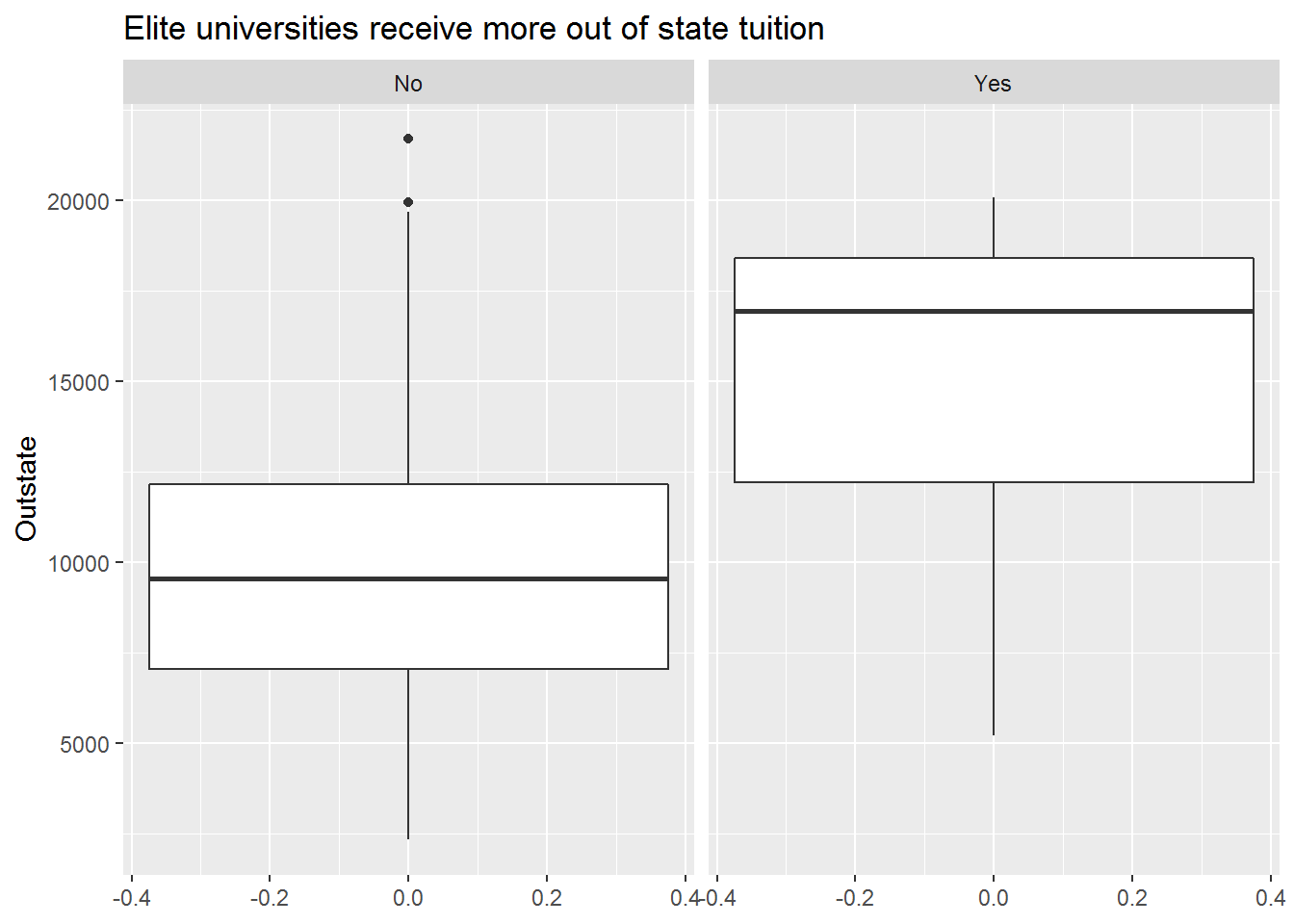
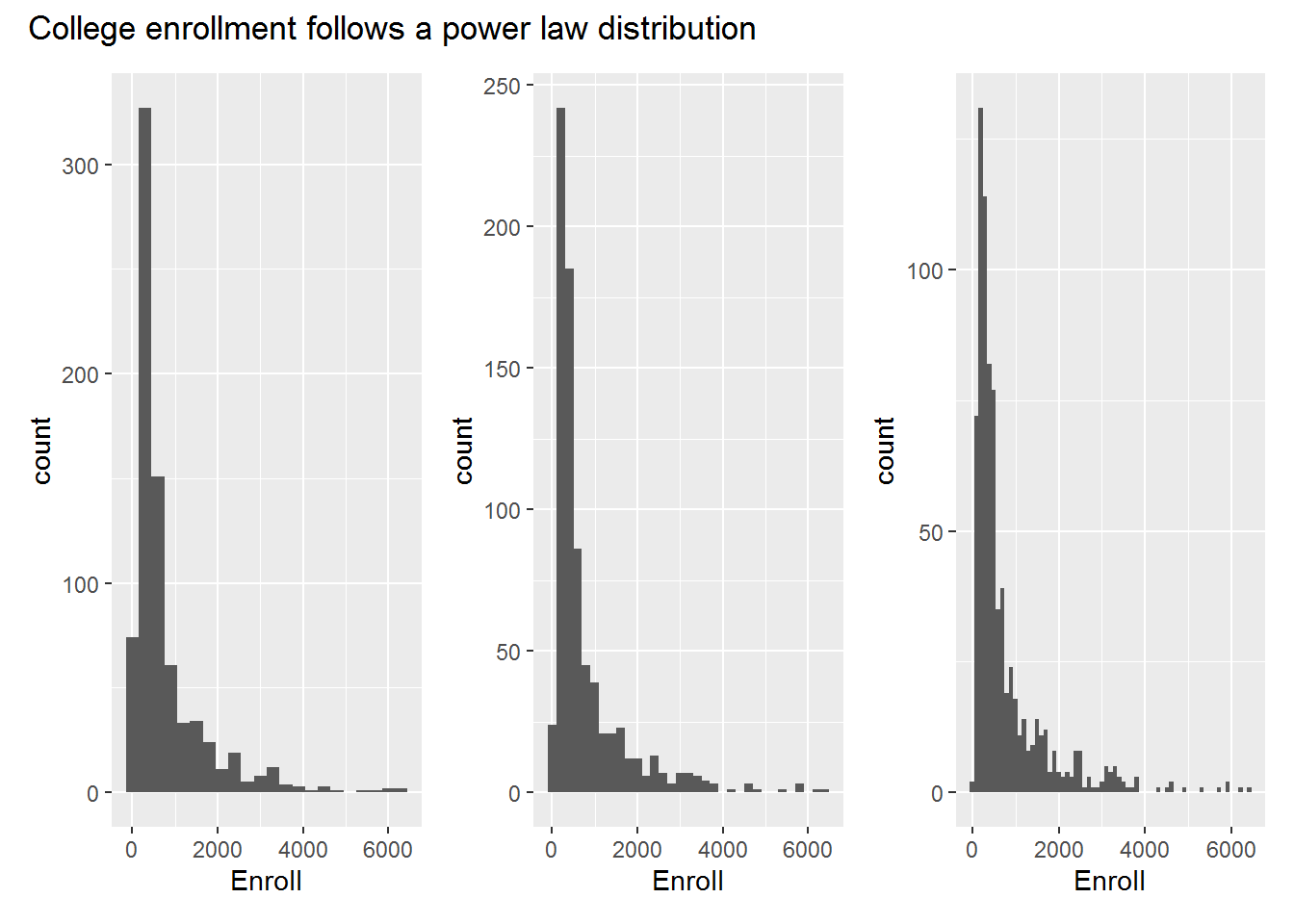
- Produce some histograms with differing numbers of bins for a few of the quantitative variables.
Answer.
gghist <- function(x, binwidth) {
ggplot(college, aes(x = {{ x }})) +
geom_histogram(binwidth = binwidth)
}
gghist(Enroll, 300) + gghist(Enroll, 200) + gghist(Enroll, 100) +
plot_annotation(
title = "College enrollment follows a power law distribution"
)
gghist(PhD, 20) + gghist(PhD, 10) + gghist(PhD, 5) +
plot_annotation(
title = "The majority of college faculty have a PhD"
)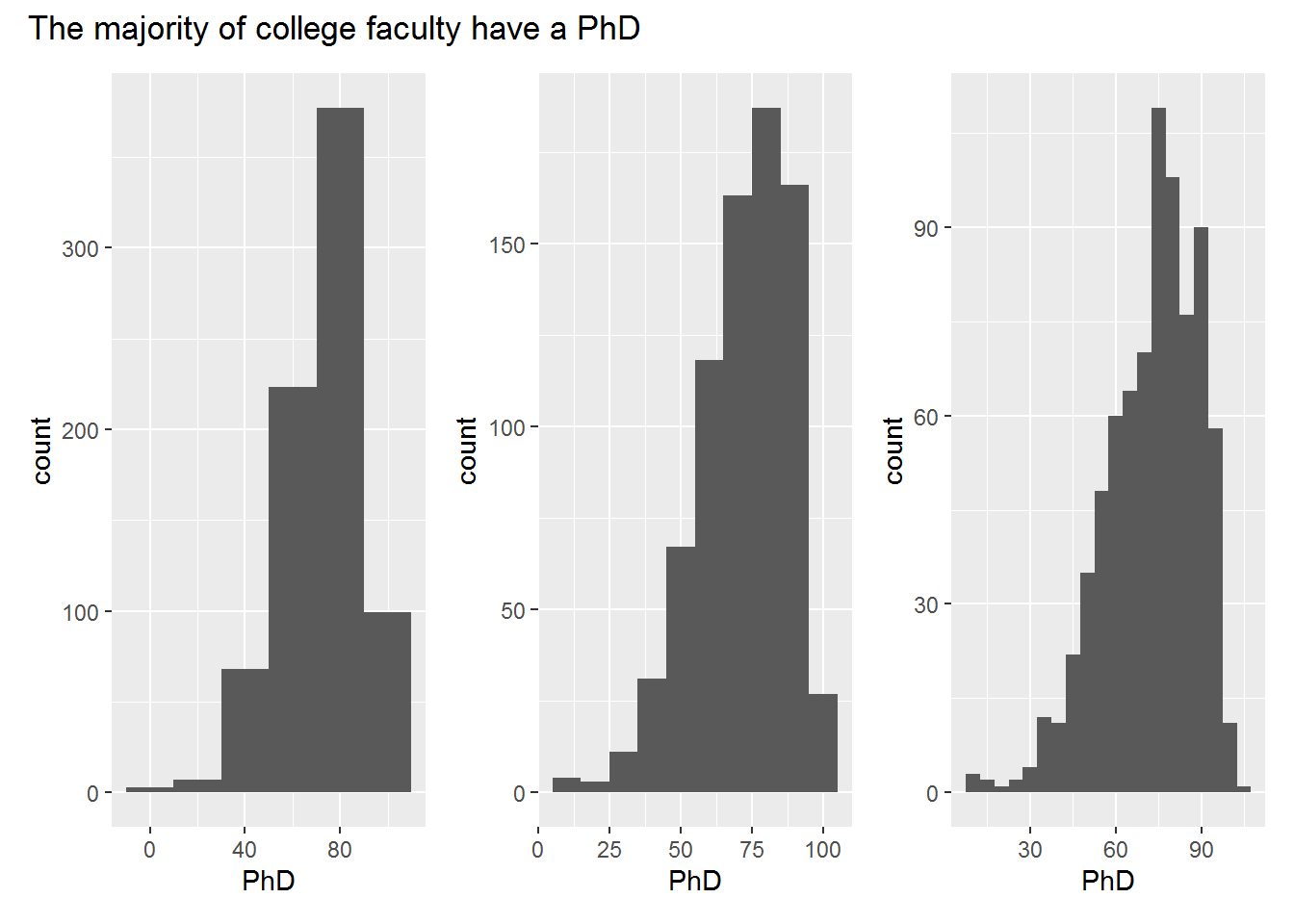
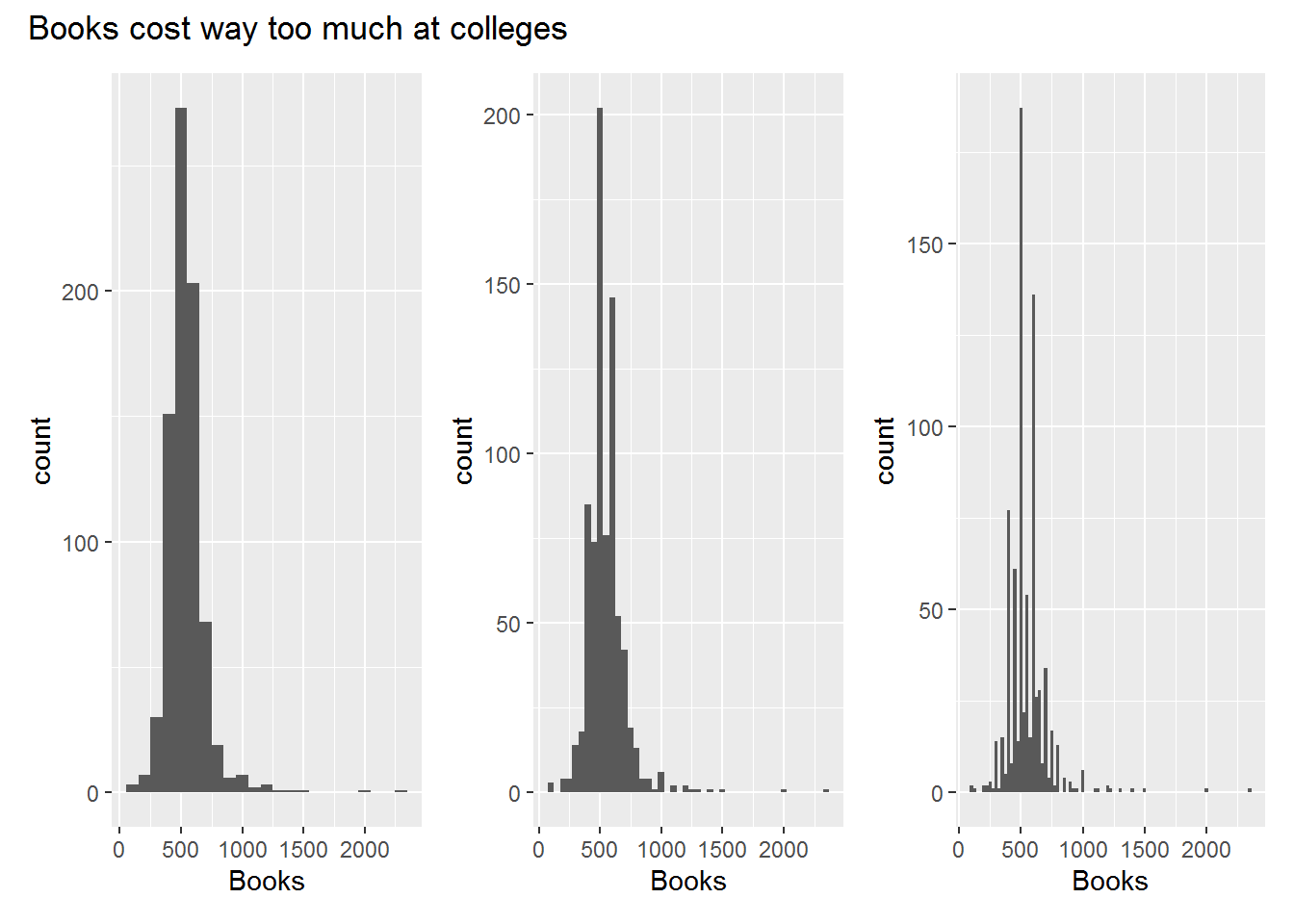
gghist(Books, 100) + gghist(Books, 50) + gghist(Books, 25) +
plot_annotation(
title = "Books cost way too much at colleges"
)
- Continue exploring the data, and provide a brief summary of what you discover.
Answer. Passing on this one.
Exercise 2.9 This exercise involves the Auto data set.
- Which of the predictors are quantitative, and which are qualitative?
Answer.
All variables but name are quantitative.
glimpse(auto)
#> Rows: 392
#> Columns: 9
#> $ mpg <dbl> 18, 15, 18, 16, 17, 15, 14, 14, 14, 1~
#> $ cylinders <int> 8, 8, 8, 8, 8, 8, 8, 8, 8, 8, 8, 8, 8~
#> $ displacement <dbl> 307, 350, 318, 304, 302, 429, 454, 44~
#> $ horsepower <int> 130, 165, 150, 150, 140, 198, 220, 21~
#> $ weight <int> 3504, 3693, 3436, 3433, 3449, 4341, 4~
#> $ acceleration <dbl> 12.0, 11.5, 11.0, 12.0, 10.5, 10.0, 9~
#> $ year <int> 70, 70, 70, 70, 70, 70, 70, 70, 70, 7~
#> $ origin <int> 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1~
#> $ name <fct> chevrolet chevelle malibu, buick skyl~What is the range of each quantitative predictor?
What is the mean and standard deviation of each quantitative predictor?
Answer.
auto %>%
pivot_longer(!name, "predictor") %>%
group_by(predictor) %>%
summarise(
min = min(value),
max = max(value),
mean = mean(value),
sd = sd(value)
)
#> # A tibble: 8 x 5
#> predictor min max mean sd
#> <chr> <dbl> <dbl> <dbl> <dbl>
#> 1 acceleration 8 24.8 15.5 2.76
#> 2 cylinders 3 8 5.47 1.71
#> 3 displacement 68 455 194. 105.
#> 4 horsepower 46 230 104. 38.5
#> 5 mpg 9 46.6 23.4 7.81
#> 6 origin 1 3 1.58 0.806
#> 7 weight 1613 5140 2978. 849.
#> 8 year 70 82 76.0 3.68- Now remove the 10th through 85th observations. What is the range, mean, and standard deviation of each predictor in the subset of the data that remains?
Answer.
auto %>%
slice(-10:-85) %>%
pivot_longer(!name, "predictor") %>%
group_by(predictor) %>%
summarise(
min = min(value),
max = max(value),
mean = mean(value),
sd = sd(value)
)
#> # A tibble: 8 x 5
#> predictor min max mean sd
#> <chr> <dbl> <dbl> <dbl> <dbl>
#> 1 acceleration 8.5 24.8 15.7 2.69
#> 2 cylinders 3 8 5.37 1.65
#> 3 displacement 68 455 187. 99.7
#> 4 horsepower 46 230 101. 35.7
#> 5 mpg 11 46.6 24.4 7.87
#> 6 origin 1 3 1.60 0.820
#> 7 weight 1649 4997 2936. 811.
#> 8 year 70 82 77.1 3.11- Using the full data set, investigate the predictors graphically, using scatterplots or other tools of your choice. Create some plots highlighting the relationships among the predictors. Comment on your findings.
Answer.
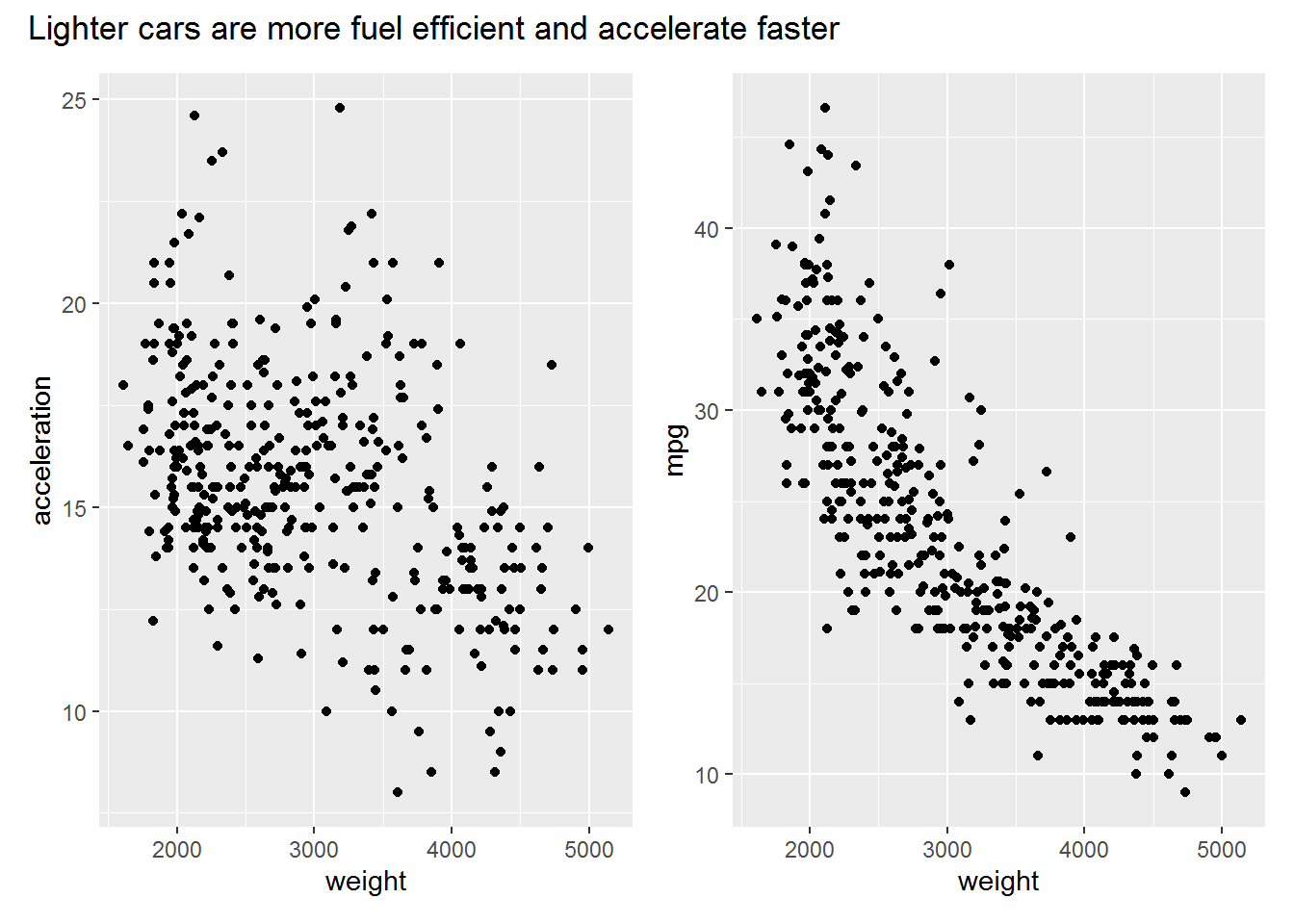
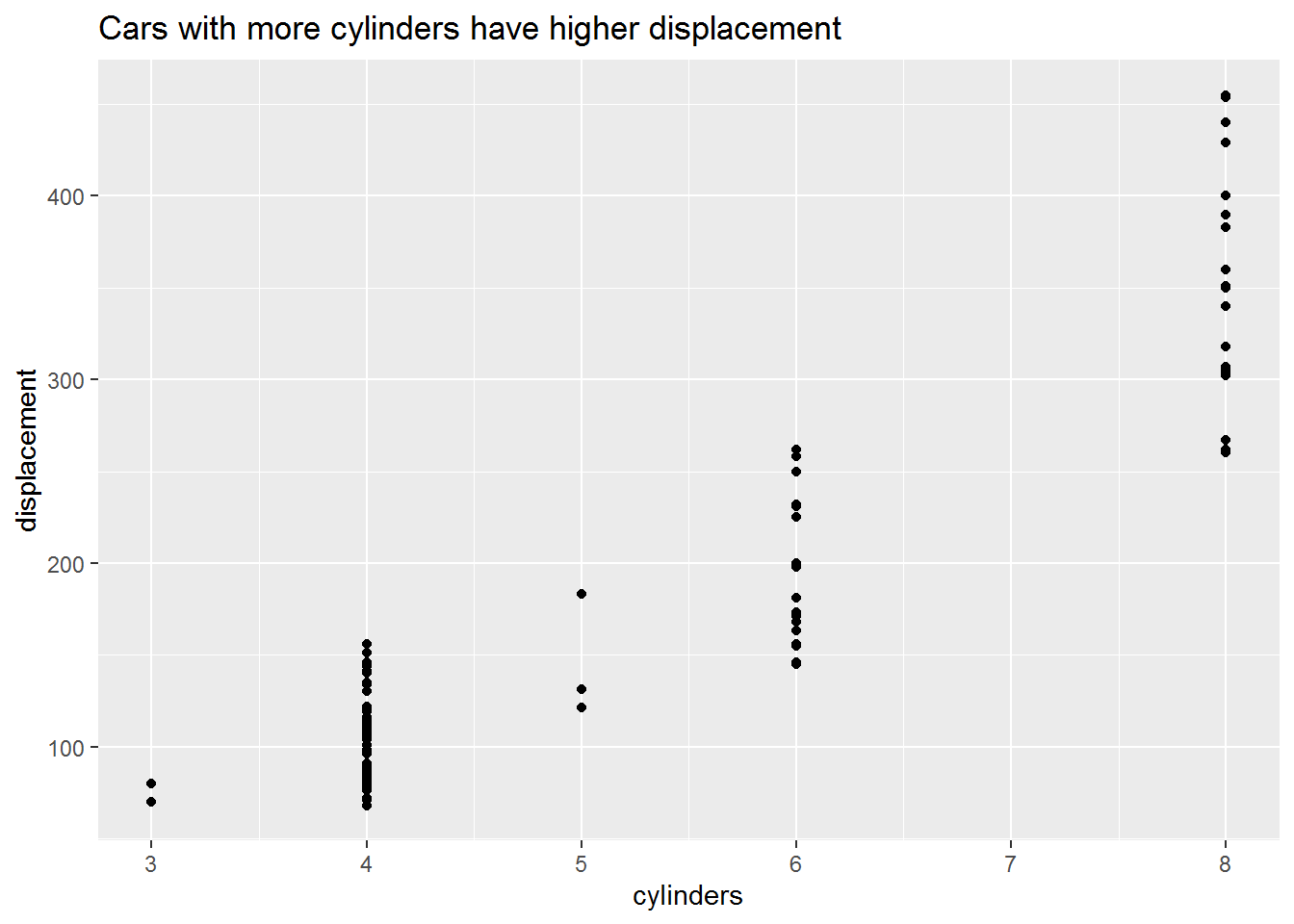
The plots below show relationships we would expect between the different variables based on the laws of physics. Some interesting observations:
- There appear to be two clusters of cars based on the weight by acceleration plot
- The relationship between weight and mpg is nonlinear
- Most cars have an even number of cylinders
ggscatter <- function(x, y) {
ggplot(auto, aes({{ x }}, {{ y }})) +
geom_point()
}
ggscatter(weight, acceleration) + ggscatter(weight, mpg) +
plot_annotation(
title = "Lighter cars are more fuel efficient and accelerate faster"
)
ggscatter(cylinders, displacement) +
labs(
title = "Cars with more cylinders have higher displacement"
)
- Suppose that we wish to predict gas mileage (mpg) on the basis of the other variables. Do your plots suggest that any of the other variables might be useful in predicting mpg? Justify your answer.
Answer.
The plots below suggest that mpg has nonlinear relationships with at least a few of the variables in the data set (I didn’t explore them all). In particular, weight and horsepower show very clear relationships that might be suitable for making predictions, so long as we can deal with the heteroskedasticity.
ggscatter(weight, mpg) + ggscatter(acceleration, mpg) +
ggscatter(horsepower, mpg) + ggscatter(displacement, mpg)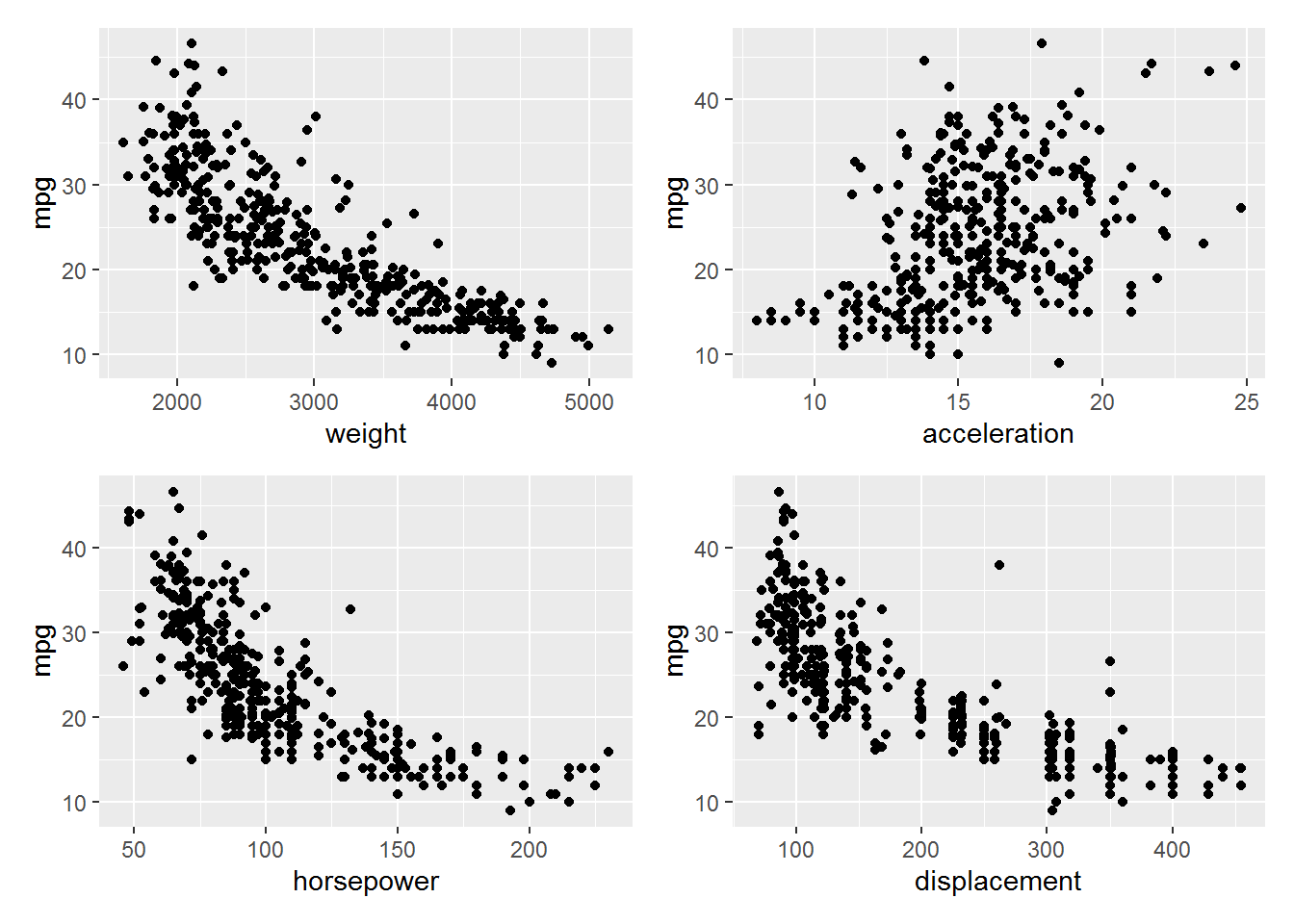
Exercise 2.10 This exercise involves the Boston housing data set.
- To begin, load in the
Bostondata set. How many rows are in this data set? How many columns? What do the rows and columns represent?
Answer.
The columns represent variables that might be related to the value of houses in an area. Each row represents a suburb in Boston.
boston <- as_tibble(ISLR2::Boston)
glimpse(boston)
#> Rows: 506
#> Columns: 13
#> $ crim <dbl> 0.00632, 0.02731, 0.02729, 0.03237, 0.0690~
#> $ zn <dbl> 18.0, 0.0, 0.0, 0.0, 0.0, 0.0, 12.5, 12.5,~
#> $ indus <dbl> 2.31, 7.07, 7.07, 2.18, 2.18, 2.18, 7.87, ~
#> $ chas <int> 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, ~
#> $ nox <dbl> 0.538, 0.469, 0.469, 0.458, 0.458, 0.458, ~
#> $ rm <dbl> 6.575, 6.421, 7.185, 6.998, 7.147, 6.430, ~
#> $ age <dbl> 65.2, 78.9, 61.1, 45.8, 54.2, 58.7, 66.6, ~
#> $ dis <dbl> 4.0900, 4.9671, 4.9671, 6.0622, 6.0622, 6.~
#> $ rad <int> 1, 2, 2, 3, 3, 3, 5, 5, 5, 5, 5, 5, 5, 4, ~
#> $ tax <dbl> 296, 242, 242, 222, 222, 222, 311, 311, 31~
#> $ ptratio <dbl> 15.3, 17.8, 17.8, 18.7, 18.7, 18.7, 15.2, ~
#> $ lstat <dbl> 4.98, 9.14, 4.03, 2.94, 5.33, 5.21, 12.43,~
#> $ medv <dbl> 24.0, 21.6, 34.7, 33.4, 36.2, 28.7, 22.9, ~- Make some pairwise scatterplots of the predictors (columns) in this data set. Describe your findings.
Answer.
I explored some other scatterplots not shown below. In general there aren’t many easily interpretable relationships between variables in this data set. Some pairs have clusters of data, but no overall trend; others have floor effects where most communities have a value of zero (e.g., crime).
ggscatter <- function(x, y) {
ggplot(boston, aes({{ x }}, {{ y }})) +
geom_point()
}
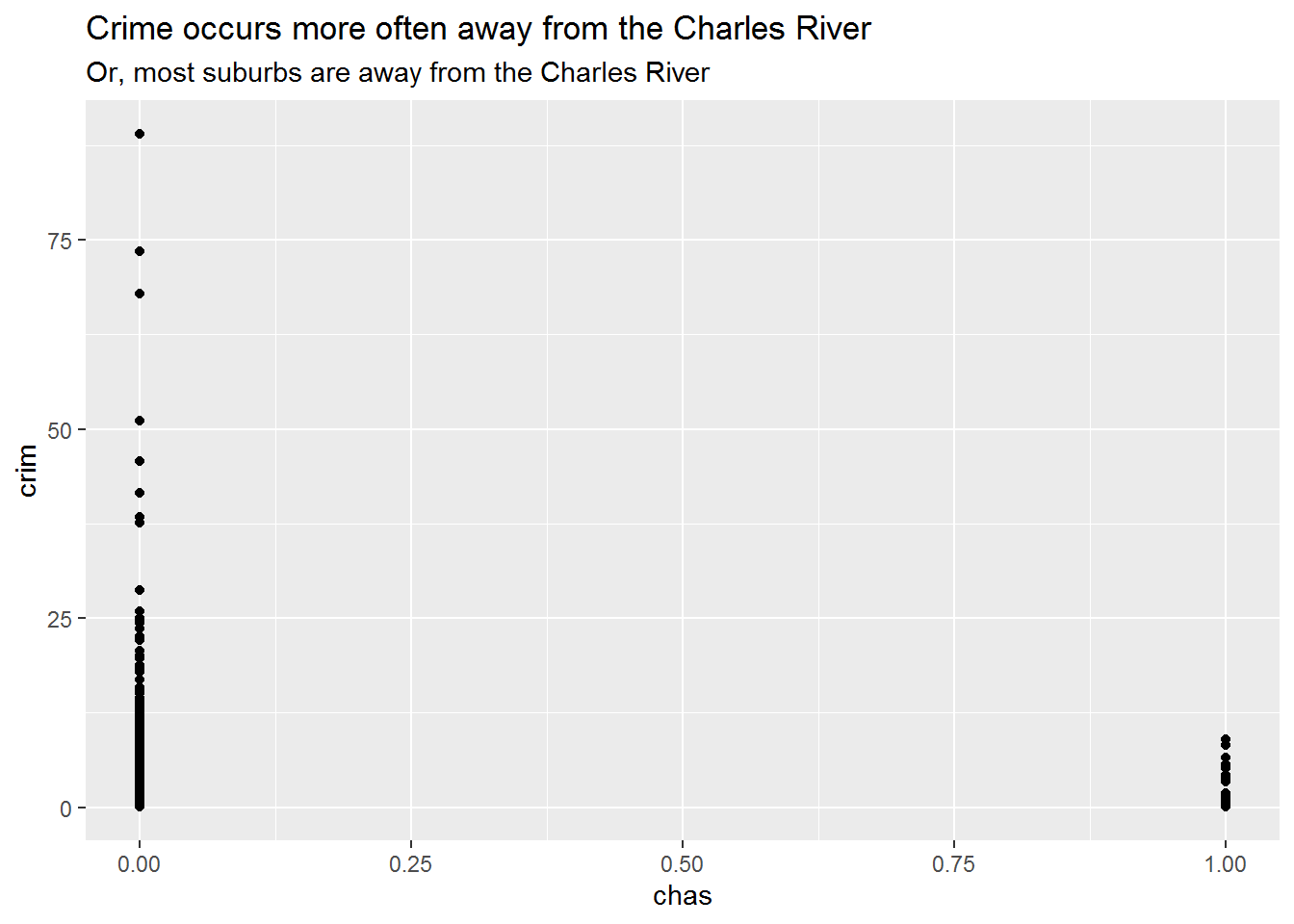
ggscatter(chas, crim) +
labs(
title = "Crime occurs more often away from the Charles River",
subtitle = "Or, most suburbs are away from the Charles River"
)
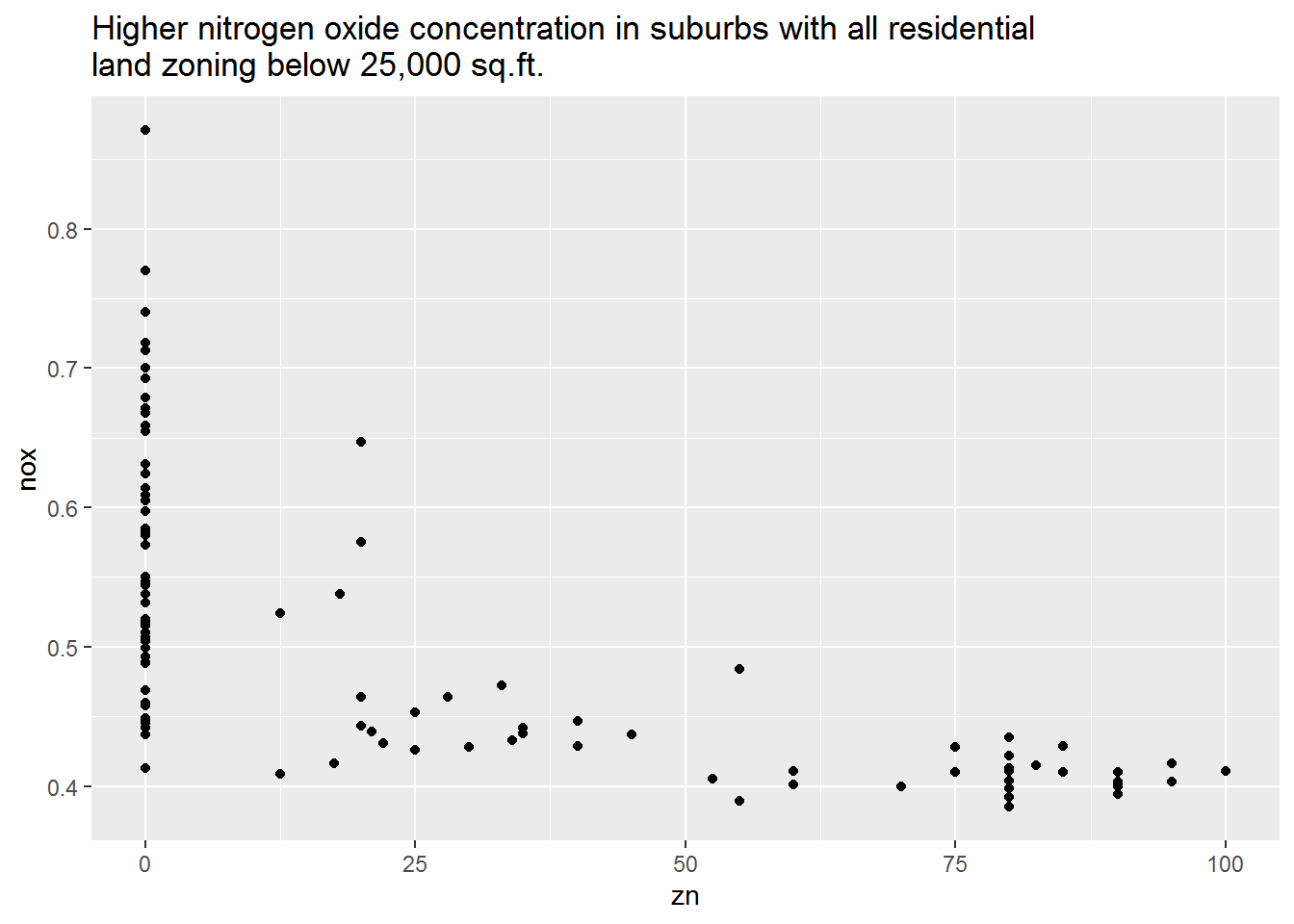
ggscatter(zn, nox) +
labs(
title = paste0(
"Higher nitrogen oxide concentration in suburbs with all residential \n",
"land zoning below 25,000 sq.ft.")
)
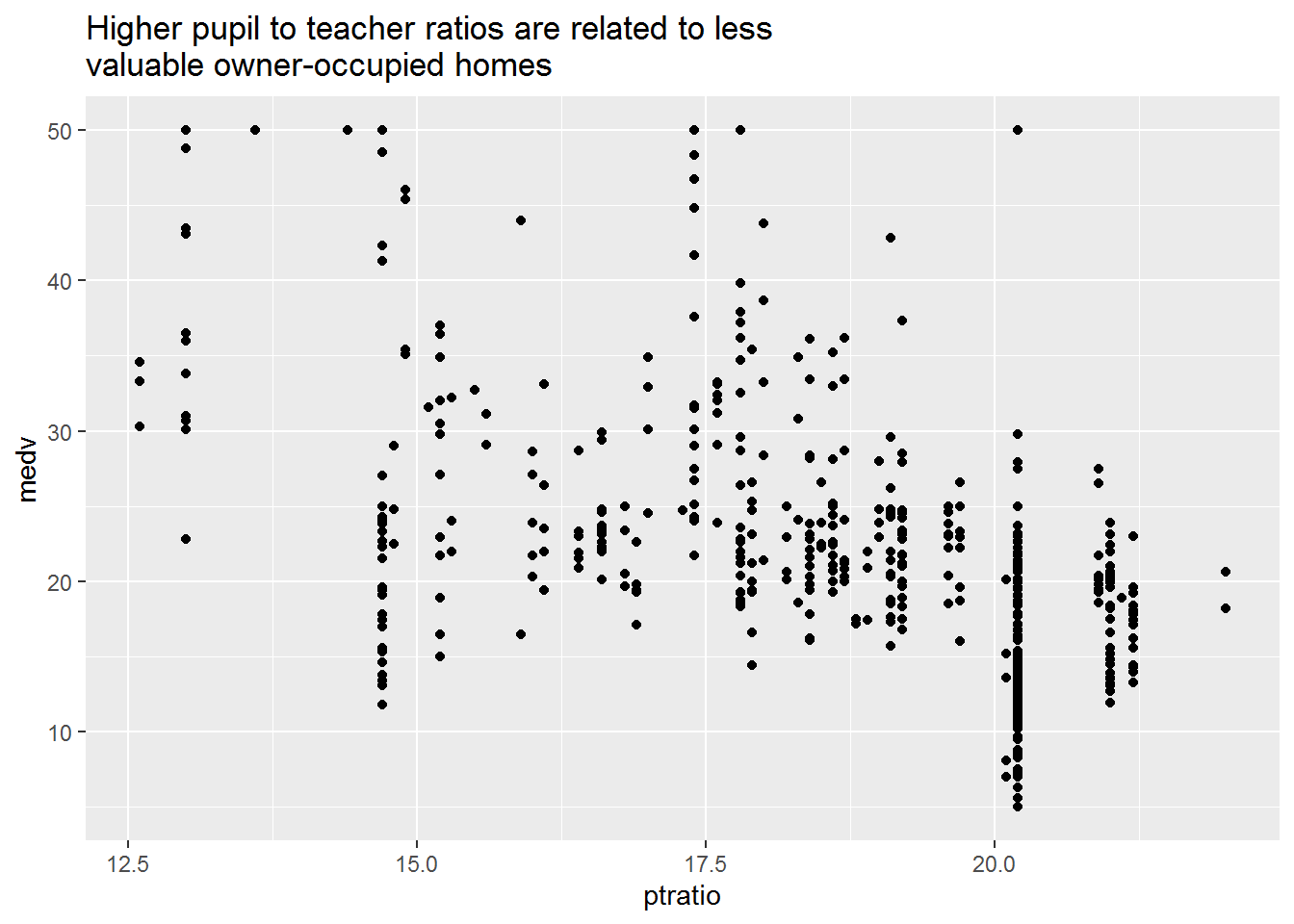
ggscatter(ptratio, medv) +
labs(
title = paste0(
"Higher pupil to teacher ratios are related to less \n",
"valuable owner-occupied homes"
)
)
- Are any of the predictors associated with per capita crime rate? If so, explain the relationship.
Answer.
The plots below are illustrative of the relationship with crime and other variables in the dataset. More or less, crime seems to occur in a specific range of the variable its being associated with.
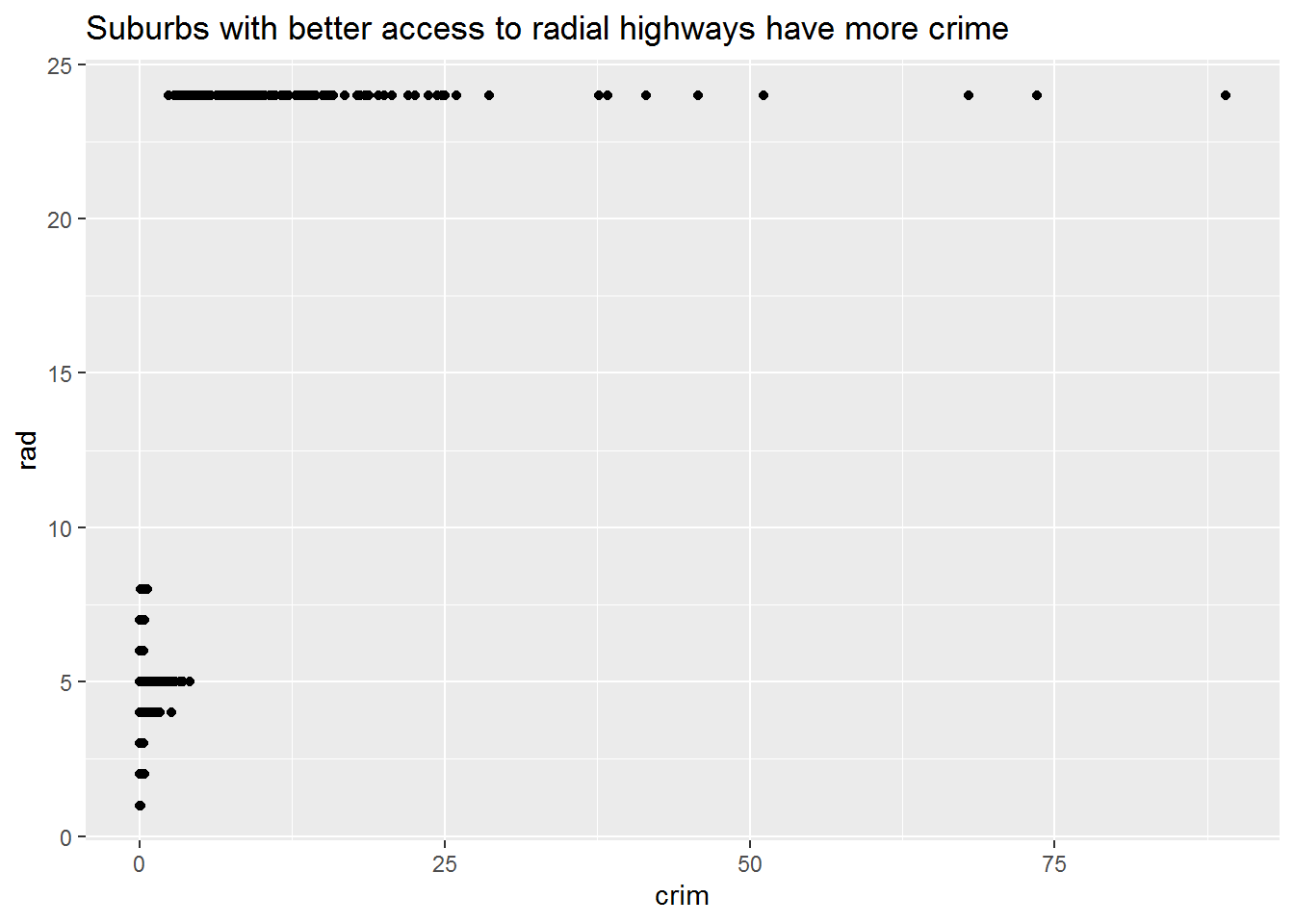
ggscatter(crim, rad) +
labs(
title = "Suburbs with better access to radial highways have more crime"
)
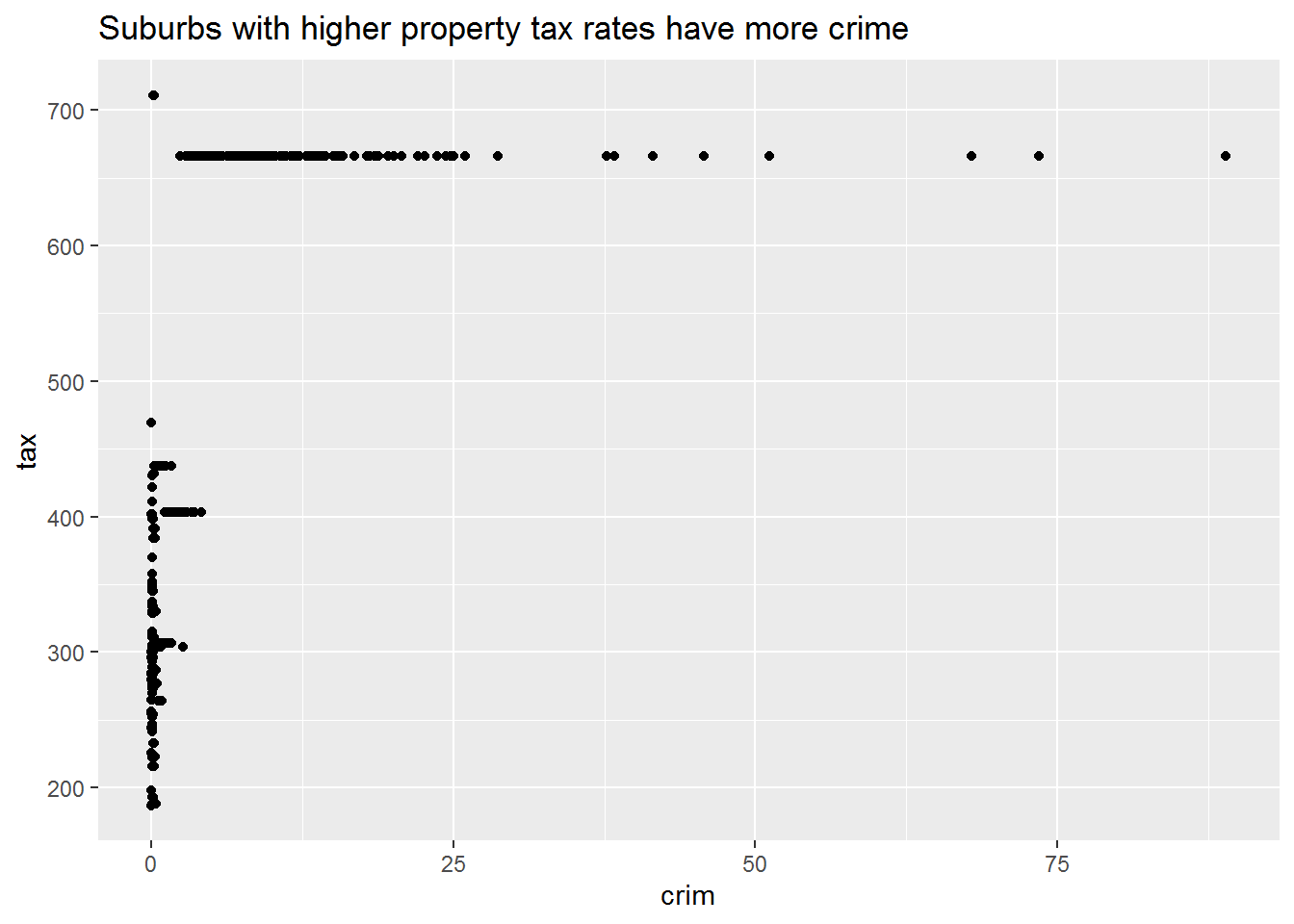
ggscatter(crim, tax) +
labs(
title = "Suburbs with higher property tax rates have more crime"
)
- Do any of the census tracts of Boston appear to have particularly high crime rates? Tax rates? Pupil-teacher ratios? Comment on the range of each predictor.
Answer.
The plots above already get at these features of the data. The range of the three predictors show some interesting patterns too. Crime per capita has a very wide range, with some having almost none and others having a lot in comparison. Tax has a similarly wide range. Although pupil-teacher ratios have a skinnier range, the differences between the minimum and maximum would be quite meaningful in a classroom—a teacher in the minimum would theoretically have twice as much time for each student compared to a teacher in the maximum.
boston %>%
select(crim, tax, ptratio) %>%
pivot_longer(everything(), "predictor") %>%
group_by(predictor) %>%
summarise(
min = min(value),
max = max(value)
)
#> # A tibble: 3 x 3
#> predictor min max
#> <chr> <dbl> <dbl>
#> 1 crim 0.00632 89.0
#> 2 ptratio 12.6 22
#> 3 tax 187 711- How many of the census tracts in this data set bound the Charles river?
Answer.
boston %>%
mutate(bound = if_else(chas == 1, "Yes", "No")) %>%
group_by(bound) %>%
summarise(
n = n()
)
#> # A tibble: 2 x 2
#> bound n
#> <chr> <int>
#> 1 No 471
#> 2 Yes 35- What is the median pupil-teacher ratio among the towns in this data set?
Answer.
boston %>%
summarise(
median_ptratio = median(ptratio)
)
#> # A tibble: 1 x 1
#> median_ptratio
#> <dbl>
#> 1 19.0- Which census tract of Boston has lowest median value of owner-occupied homes? What are the values of the other predictors for that census tract, and how do those values compare to the overall ranges for those predictors? Comment on your findings.
Answer.
The suburb with the lowest median value of owner-occupied homes and the values of the other predictors for it are listed here.
boston %>%
arrange(desc(medv)) %>%
tail(1) %>%
glimpse()
#> Rows: 1
#> Columns: 13
#> $ crim <dbl> 67.9208
#> $ zn <dbl> 0
#> $ indus <dbl> 18.1
#> $ chas <int> 0
#> $ nox <dbl> 0.693
#> $ rm <dbl> 5.683
#> $ age <dbl> 100
#> $ dis <dbl> 1.4254
#> $ rad <int> 24
#> $ tax <dbl> 666
#> $ ptratio <dbl> 20.2
#> $ lstat <dbl> 22.98
#> $ medv <dbl> 5In comparison to the range of those values:
-
crimis at the upper end -
znis at the minimum -
indusis around two-thirds up - The suburb does not bound the river
-
noxis at the upper end -
rmis near the middle -
ageis at the maximum -
disis almost at the minimum -
radis at the maximum -
taxis near the maximum -
ptratiois near the maximum -
lstatis around two-thirds up -
medvis at the minimum
boston %>%
pivot_longer(everything(), "predictor") %>%
group_by(predictor) %>%
summarise(
min = min(value),
max = max(value)
)
#> # A tibble: 13 x 3
#> predictor min max
#> <chr> <dbl> <dbl>
#> 1 age 2.9 100
#> 2 chas 0 1
#> 3 crim 0.00632 89.0
#> 4 dis 1.13 12.1
#> 5 indus 0.46 27.7
#> 6 lstat 1.73 38.0
#> 7 medv 5 50
#> 8 nox 0.385 0.871
#> 9 ptratio 12.6 22
#> 10 rad 1 24
#> 11 rm 3.56 8.78
#> 12 tax 187 711
#> 13 zn 0 100It is unsurprising that this suburb has the lowest median value of owner-occupied homes. It is an older suburb with small residential lots, high traffic and density with a resultant increase in pollution and crime, most of the land is taken up by businesses, and high taxes. Most of these characteristics are not attractive to home buyers, so there likely isn’t much demand for homes in this suburb.
- In this data set, how many of the census tracts average more than seven rooms per dwelling? More than eight rooms per dwelling? Comment on the census tracts that average more than eight rooms per dwelling.
Answer.
Several of these communities seem to be near each other, given the shared values between many of their variables. Most have low tax rates, low crime, smaller lots, medium to high pollution, and a high number of rooms per dwelling.
boston %>%
filter(rm > 8)
#> # A tibble: 13 x 13
#> crim zn indus chas nox rm age dis rad
#> <dbl> <dbl> <dbl> <int> <dbl> <dbl> <dbl> <dbl> <int>
#> 1 0.121 0 2.89 0 0.445 8.07 76 3.50 2
#> 2 1.52 0 19.6 1 0.605 8.38 93.9 2.16 5
#> 3 0.0201 95 2.68 0 0.416 8.03 31.9 5.12 4
#> 4 0.315 0 6.2 0 0.504 8.27 78.3 2.89 8
#> 5 0.527 0 6.2 0 0.504 8.72 83 2.89 8
#> 6 0.382 0 6.2 0 0.504 8.04 86.5 3.22 8
#> 7 0.575 0 6.2 0 0.507 8.34 73.3 3.84 8
#> 8 0.331 0 6.2 0 0.507 8.25 70.4 3.65 8
#> 9 0.369 22 5.86 0 0.431 8.26 8.4 8.91 7
#> 10 0.612 20 3.97 0 0.647 8.70 86.9 1.80 5
#> 11 0.520 20 3.97 0 0.647 8.40 91.5 2.29 5
#> 12 0.578 20 3.97 0 0.575 8.30 67 2.42 5
#> 13 3.47 0 18.1 1 0.718 8.78 82.9 1.90 24
#> # ... with 4 more variables: tax <dbl>, ptratio <dbl>,
#> # lstat <dbl>, medv <dbl>